A pesar de haber leído guías tan buenas como:
https://medium.com/@bogdan.cojocar/how-to-run-scala-and-spark-in-the-jupyter-notebook-328a80090b3b
Se me ha hecho cuesta arriba el poder conectar un notebook de jupyter y utilizar Scala. Entre configurar el apache toree para poder usar scala en los notebooks y algún error luego en spark al usarlo desde IntelliJ, me he acabado rindiendo.
Nota del autor: Como disclaimer esto ocurre probablemente porque estoy en Manjaro y mi version de Scala es incompatible. Esta clase de problemas en su día las solucionaba fijando una versión, sin embargo, creo que teniendo una herramienta tan potente como es Docker estoy reinventando la rueda par un problema ya resuelto. Además de que voy a probarlo también en un windows para ver que es una solución agnóstical SO.
No voy a profundizar en nada de docker, simplemente podemos verlo como una “virtualización ligera” que se alimenta de imágenes para ejecutar procesos. Para el caso de configurar Spark con Jupyter podemos utilizar esta imagen de docker para nuestro propósito: https://hub.docker.com/r/jupyter/all-spark-notebook/
Tras ejecutar el comando docker pull jupyter/all-spark-notebook y descargar los 2 GB de imagen:
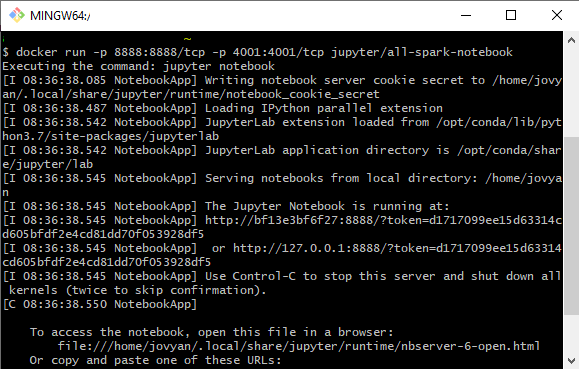
Ya solo nos quedaría arrancar el proceso. Para esto tenemos que mapear tres puertos del entorno de docker a nuestra máquina. Esto se hace en el propio comando de arranque
docker run -p 8888:8888/tcp -p 4040:4040/tcp jupyter/all-spark-notebook
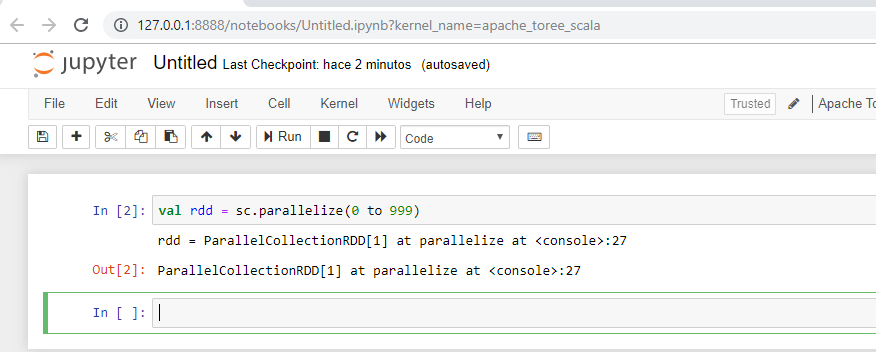
Si copiamos la url que nos aparece, haremos el token de forma automática y podremos acceder a los notebook y ejecutar comandos de scala:
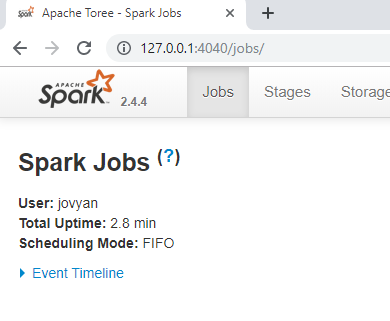
Y además en el puerto 4040 tendremos la spark ui para revisar nuestras ejecuciones:
Con esto, ya podemos practicar con Spark sin afectar a la configuración que tengamos en nuestra máquina.
Extra
De forma opcional, vamos a montar un directorio en docker y vamos a ejecutar un job en Spark utilizando el comando spark-submit.
Lo primero, es que si estamos en Windows debemos compartir nuestro disco con docker, simplemente vamos a Settings -> Shared Drivers y habilitamos el disco.
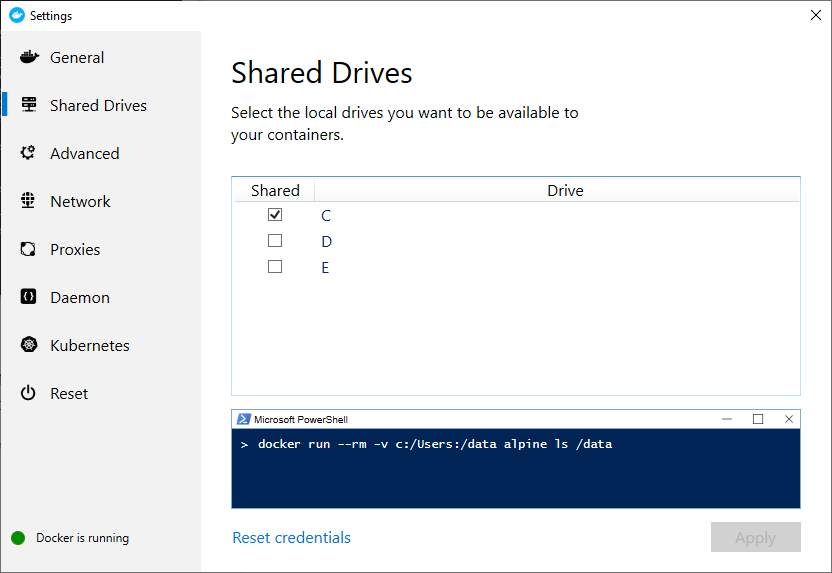
Ahora necesitamos montar el directorio y esto lo haremos al arrancar la imagen. El comando sería:
docker run -p 8888:8888/tcp -p 4040:4040/tcp -v c:/spark-demo:/data jupyter/all-spark-notebook
Y en el notebook de jupyter abrimos una terminal para validarlo:
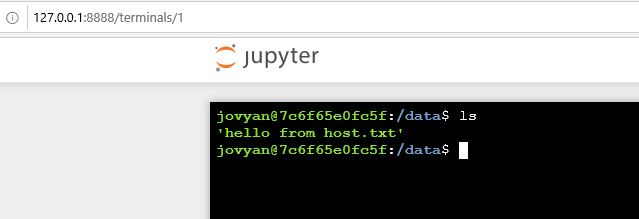
Ahora que ya tenemos esto, la idea es ver como sería un entorno “productivo” de Spark, más allá de los notebooks y mandar un spark job utilizando el punto de entrada de spark submit.
Nuestro programa no hará gran cosa, solo se trata de una aplicación de Scala que genera 500 numeros y los cuenta según sean múltiplos de 3 o no. (No hay que centrarse en el código). La parte más importante es que necesitamos mandar un assembly jar. Es decir, un jar que contiene sus dependencias. Todo esto está documentado por Spark aquí: https://spark.apache.org/docs/latest/submitting-applications.html
Para poder crear el assembly vamos a utilizar sbt y el plugin https://github.com/sbt/sbt-assembly
Para poder dejar el articulo más ligero os dejo un enlace al repositorio de github con el código.
https://github.com/adrianabreu/spark-multiple-of-3
Simplemente tenemos que ejecutar el comando “sbt assembly” para generar un jar y este jar lo ponemos en la carpeta del docker.
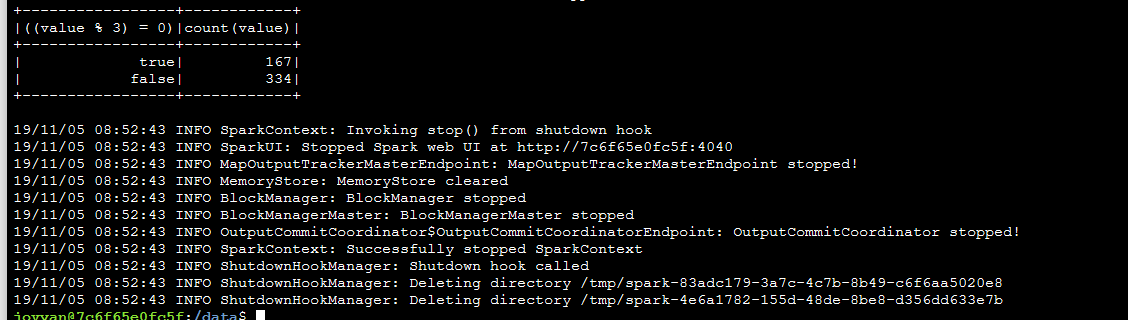
Ahora utilizaremos el comando de spark-submit para mandar el job.
/usr/local/spark/bin/spark-submit --class "example.Application" multiple-of-3-assembly-1.0.0.jar
Et voilá!
FAQ:
Si hay algún error con puertos y al intentar rearrancar la imagen de docker aparece que los puertos estan en uso, basta con hacer un docker ps -a copiar el container id y hacer un docker kill containerid.