En analítica, es muy común hacer uso de las funciones de ventana para distintos cálculos. Hace poco me encontré con un pequeño problema cuya solución mejoró muchísimo al usar las funciones de ventana, demos un poco de contexto.
Tenemos una dimensión de usuarios donde los usuarios se van registrando con una fecha y tenemos una tabla de ventas donde tenemos las ventas globales para cada día
Y lo que queremos dar es una visión de cómo cada día evoluciona el programa, para ello se quiere que cada día estén tanto las ventas acumuladas como los registros acumulados.
Asumamos que no hay ninguna dimensión de fecha y que solo contamos con estos datos, no es necesario mostrar datos en fechas en los que no ha ocurrido nada.
| DateKey | Users |
|---|---|
| 1 | 2 |
| 3 | 1 |
| DateKey | Sales |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 5 |
Y lo que queremos obtener sería algo como esto:
| DateKey | AccumulatedSales | AccumulatedUsers |
|---|---|---|
| 1 | 2 | 2 |
| 2 | 5 | 2 |
| 3 | 10 | 3 |
Para este problema con las herramientas habituales acababa generando un “monstruo” de tabla temporal que superaba con creces el tamaño de la tabla final, solo para tener acceso a otras filas mientras trabajaba con ellas.
Y aquí es donde entran las funciones de ventana. Pero dada la complejidad del concepto, voy a intentar profundizar en ello lo mejor posible.
Normalmente cuando trabajamos con los datos en una consulta, lo hacemos a nivel de fila o a nivel de grupo. Podemos o seleccionar un valor de una fila o agregar la información. Las funciones de ventana nos permiten calcular para una fila x un valor que dependa de sus filas adyacentes.
Para esto hay que entender las tres partes que componen la función de ventana:
-
Partitioning: En base a una expresión las filas con este criterio se “mueven” a un mismo conjunto (partición). No reduce los valores a únicos, como haría un group by. Si no se específica una cláusula de partitioning, se considera que todas las filas pertenencen a la misma partición.
-
Ordering: Dentro de cada partición podemos ordenar las filas, es decir podemos hacer un ordenamiento es local. El mejor ejemplo de uso de este ordenamiento son las funciones de rank: row_number, rank, dense_rank….
-
Framing: Una vez hemos determinado la partición, para algunas funciones podemos “restringir” los valores sobre los que actuará la ventana. Existen dos modos de hacerlo, uno es el modo rows, que trata cada fila como un valor único, el otro es range, que se apoya en el order by. Para mi la forma de entenderlo ha sido pensar en el rank, a dos valores iguales de order by, les corresponde el mismo valor de rank, pues en este caso la ventana les asigna el mismo valor calculado.
En el paper de Viktor Leis [1], se proporciona una imagen que da un buen contexto:
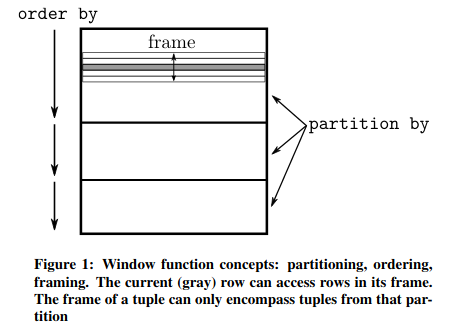
Y con esto definido podemos usar una windows function para resolver el problema.
Lo primero que haremos será simplemente unir los dos usuarios:
val df = sales.join(users, Seq(“DateKey”), “left”)
Ahora, tendriamos todos los datos tal que así:
| DateKey | Sales | Users |
|---|---|---|
| 1 | 2 | 2 |
| 2 | 3 | null |
| 3 | 5 | 1 |
Para poder general una función de ventana, tenemos que importar el paquete: org.apache.spark.sql.expressions.Window
Nos interesa una ventana en la que cuya partición englobe a todas las filas, es decir, que no haya particionado.
Ahora ordenaremos las filas por datekey de manera ascendente
val w1 = Window.partitionBy().orderBy(col(“DateKey”).asc)
Realmente esto es equivalente a su valor por defecto de no poner el partitionBy, quedando así:
val w1 = Window.orderBy(col(“DateKey”).asc)
Y por ultimos nos falta definir el frame que determine que filas hemos de coger. Como no hay duplicados será indistinto. [3]
val w1 = Window.orderBy(col(“DateKey”).asc).rangeBetween(Window.unboundedPreceding, Window.currentRow)
Y de nuevo, nos encontramos utilizando el valor por defecto de framing.
Si revisamos un plan de ejecución podemos ver el windowsspecdefinition:
windowspecdefinition(day1#50 ASC NULLS FIRST, specifiedwindowframe(RangeFrame, unboundedpreceding$(), currentrow$())) AS
Y con la versión simplificada
val w1 = Window.orderBy(col(“DateKey”).asc)
Obtenemos el mismo plan
specifiedwindowframe(RangeFrame, unboundedpreceding$(), currentrow$())) AS
Ahora podemos aplicar a nuestro dataframe la funcion de ventana a través de un select por ejemplo.
df.select(
col(“DateKey”)
sum(“sales”) over w1 as "AccumulatedSales"
sum(“users”) over w1 as "AccumulatedUsers"
)
Y obtenemos el resultado anteriormente comentado.
Bibliografia:
[1] https://vldb.org/pvldb/vol5/p1244_yucao_vldb2012.pdf
[2] https://www.vldb.org/pvldb/vol8/p1058-leis.pdf
[3] https://www.sqlpassion.at/archive/2015/01/22/sql-server-windowing-functions-rows-vs-range/