Sorprendentemente, hasta ahora, no había tenido la posibilidad de trabajar con data factory, sólo lo habia usado para algunas migraciones de datos.
Sin embargo, tras estabilizar un proyecto y consolidar su nueva etapa, necesitabamos simplificar la solución implementada para migrar datos.
Una representación sencilla de la arquitectura actual sería:
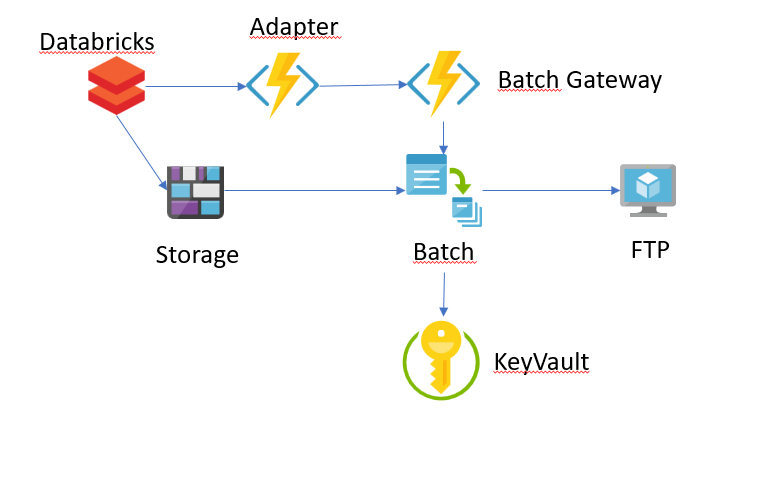
En un flujo muy sencillo sería esto:
- La etl escribe un fichero csv con spark en un directorio de un blob storage.
- La primera function filtra los ficheros de spark que no son part- y se encarga de notificar a una function que actua de gateway para el batch con que fichero queremos enviar, el nombre original, el path y el nombre que queremos darle.
- Esta function de gateway se encarga de realizar las llamadas necesarias a la api de Azure para generar una tarea en el batch.
- El batch se encarga de comprimir el fichero y enviarlo al sftp del cliente, recuperando las credenciales según el tipo de fichero que se trate.
Este proceso nos permitía trabajar con dos versiones del proyecto en lo que hacíamos la migración a la nueva versión. Ahora que la nueva versión ya está consolidada y hemos conseguido además que el cliente utilice un formato de compresión que podemos escribir directamente desde spark sin recurrir al batch, es el momento de cambiar la arquitectura de transferencia de datos.
Pues todas esta arquitectura se ha simplificado en: Data Factory.
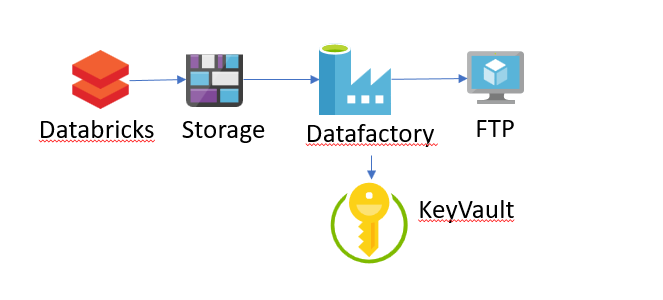
Lo primero que teníamos que resolver era el renombrado del fichero. Al final desde la propia API de hadoop se puede realizar este renombrado sin atacar directamente a la implementación por debajo.
Ahora, tenemos que construir nuestra pipeline de data factory.
Lo primero que haremos será configurar los linked services, en nuestro caso son tres:
- El storage del que vamos a extraer los ficheros.
- El sftp al que queremos atacar. Como curiosidad este servicio requiere de un “Integration Runtime” que actuará de puente para esta tarea. Yo he configurado una máquina en West Europe con los parámetros por defecto.
- El key vault del que queremos recuperar la contraseña. (¡No nos olvidemos de dar permisos de acceso a los secretos a la aplicación de data factory en el azure active directory!) y le ponemos los datos por ahora de manera estática.
La configuración de los mismos es muy visual y no requiere nada en especial.
Configuramos dos datasets, uno de origen asociado al storage que reciba dos parámetros y que usaremos para discriminar el path del fichero.
{
"name": "Binary1",
"properties": {
"linkedServiceName": {
"referenceName": "LinkedServiceAzureBlobStorage",
"type": "LinkedServiceReference"
},
"parameters": {
"FPath": {
"type": "string"
},
"FName": {
"type": "string"
}
},
"annotations": [],
"type": "Binary",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": {
"value": "@dataset().FName",
"type": "Expression"
},
"container": {
"value": "@dataset().FPath",
"type": "Expression"
}
}
}
},
"type": "Microsoft.DataFactory/factories/datasets"
}
Y otro de sink. Sin parámetros.
Configuramos la acitvity de copy data con ambos y estaría casi todo, nos falta saber que fichero queremos leer. Marcamos la opción en el source de ‘File path in dataset’ y nos dedicamos a configurar dos parámetros para la pipeline que usaremos aquí.
"parameters": {
"sourcePath": {
"type": "string"
},
"sourceName": {
"type": "string"
}
}
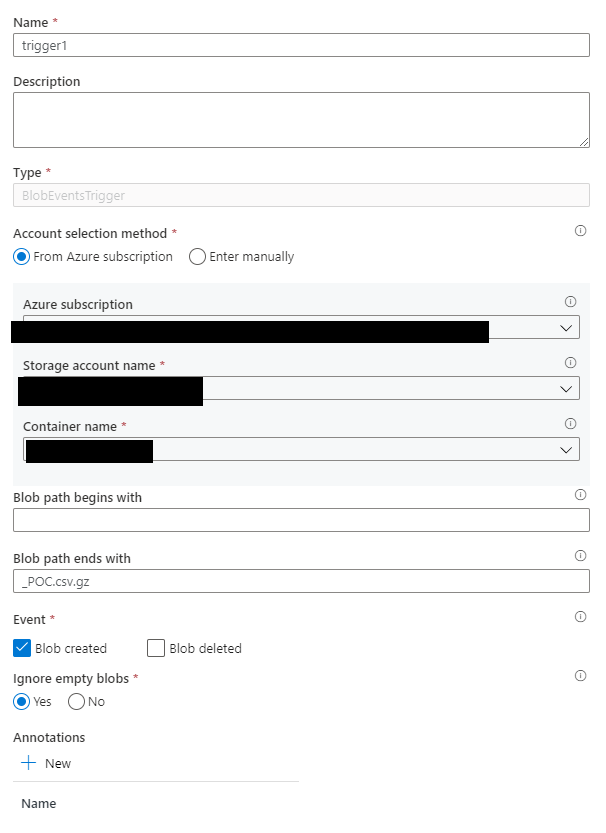
La idea es que esta pipeline la dispare un blob trigger asociado al storage. Este blob trigger presenta dos parametros de folderPath y fileName.
sourcePath - @trigger().outputs.body.folderPath
sourceName - @trigger().outputs.body.fileName
Ahora configuraremos el blob trigger. Añadimos un sufijo para que no nos molesten los otros ficheros (incluyendo el primer fichero que escribiremos desde spark previo al renombrado):
Ya tenemos nuestra pipeline en marcha, si subimos un fichero podremos monitorizar como este se envia al ftp.
Sin embargo, antes comenté que dependiendo del fichero tenía que usar unas credenciales u otras. Y aquí es donde la cosa se complica
Para que entendamos el problema, quiero que el fichero que acabe en PL_POC.csv.gz coja las credenciales asociadas a “PL”. De tal manera que haya un usuario por país en un modelo internacional.
Así que necesitamos hacer dos cosas, primero tenemos que parametrizar el linked service del ftp para que acepte parámetros, y segundo, tenemos que buscar las credenciales que corresponden.
Para lo primero tenems que hacer uso de las dynamic properties de los linked services, cuyo problema es que solo se puede hacer directamente desde el json, no tiene ayuda visual como el resto. Dejo aquí un json de ejemplo:
{
"name": "SftpSink",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"parameters": {
"UserNameParameter": {
"type": "string",
"defaultValue": "defaultValue"
}
},
"annotations": [],
"type": "Sftp",
"typeProperties": {
"host": "ftp.mydomain.com",
"port": 22,
"skipHostKeyValidation": true,
"authenticationType": "Basic",
"userName": "@{linkedService().UserNameParameter}",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "AzureKeyVault1",
"type": "LinkedServiceReference"
},
"secretName": "MyLinkedService"
}
}
}
}
Como vemos declaramos un parámetro en la sección de parameters y lo referenciamos usando el @linkedService()
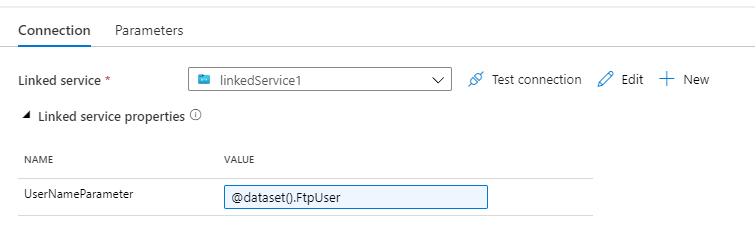
Ahora podemos ponerle un parámetro a nuestro dataset de sink y pasarselo al linked service:
Ahora viene el momento de extraer la información del nombre del fichero, en este caso tenemos que jugar con las funciones disponibles: length, sub, y substring.
Ejemplo: Stock_RU_POC.csv.gz
substring(pipeline().parameters.sourceName,sub(length(pipeline().parameters.sourceName),13),2)
Resultado: RU
Ahora tenemos en una cadena el país correspondiente. En mi caso he recurrido a un fichero de configuración y he hecho un lookup sobre el mismo. He utilizado una tarea de filter para discriminar las entradas que no me interesaban, simplemente con un:
@equals(item().Country,substring(pipeline().parameters.sourceName,sub(length(pipeline().parameters.sourceName),13),2) )
Ahora en el output del filter tenemos solo los elementos que han pasado el criterio:
{
"ItemsCount": 2,
"FilteredItemsCount": 1,
"Value": [
{
"Country": "RU",
"User": "myRussianUser"
}
]
}
Como vemos en el resultado del filtro tenemos acceso a un objeto que tiene un valor númerico con el número de resultados que han pasado el filtro.
Ahora podemos añadir un if que se encargue de validar de que haya un resultado, quedando así la pipeline:
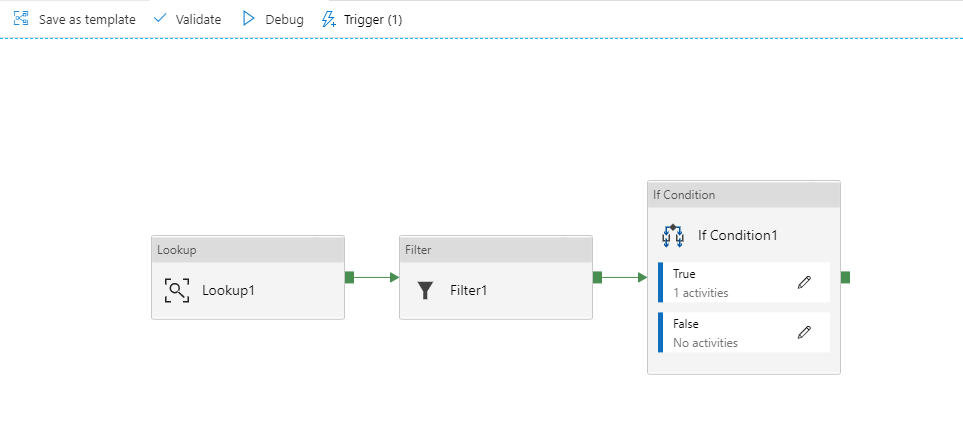
Ahora, como último paso me he encontrado con una degradación del rendimiento, en la solución creada en Azure Batch el tiempo estimado para enviar 2GB era de ~30 minutos. En mi primera prueba, he acabado tardando 2 horas aproximadamente.
Hay una sección dedicada a esto en la documentación de microsoft. Básicamente monitorzando la actividad me di cuenta de que el problema estaba en el sink write, y recurriendo a esta guia de microsoft movi el integration runtime de región a East US, donde estaba alojado el sftp de destino.
¿El resultado? Un tiempo de 25 minutos, mejor que en mi solución del batch.
Referencias:
https://docs.microsoft.com/en-us/azure/data-factory/control-flow-expression-language-functions https://docs.microsoft.com/en-us/azure/data-factory/parameterize-linked-services https://stackoverflow.com/questions/61272370/sftp-connection-customization-parameterization